
In January 2025, we closed 262 tasks and completed 462 deployments. Among the key updates, we introduced Crowdin.ai in beta, offering AI-powered localization aimed at indie developers, focusing on faster turnarounds. Additionally, the new Vector Memory App helps improve translation accuracy by using non-bilingual, relevant, translated files as reference. We also enhanced our Translation Costs and Cost Estimate reports by adding weighted word counts and more.
Introducing crowdin.ai: AI-First Continuous Localization for Developers
We’re excited to announce our new product — Crowdin.ai It’s an ambitious experiment designed for indie developers, small teams, and any project that can accept a small risk of less-than-perfect translations in exchange for faster turnaround and reduced costs. We recognize that AI translations may not always be error-free, but after extensive experimentation, we believe we have developed a set of tools to make them reliably “good enough” for many real-world scenarios.
This is a very early beta, and we’re still refining the experience. While AI-driven localization has potential, we see it as most beneficial for individual developers rather than teams (for now).
Why use crowdin.ai instead of just using AI in your IDE or LLM chat window?
-
Context for better results: When requesting translations, we provide the LLM with valuable context (for each key) extracted from source code and metadata - so it can produce more accurate translations.
-
Continuous, consistent localization: Crowdin.ai acts as an AI agent that runs in your CI/CD pipeline, delivering translations that are consistent with previous translations and your app domain each time you create new content in the source language.
-
Quality tools: Features such as back-translation preview in your language, bad context detection to predict potentially bad translations, and key-level editing (without knowing the target language) help developers find and fix errors quickly.
-
Upgrade to professional linguistic review: If one day you need the guaranteed quality or more localization tools, you can upgrade to a Crowdin.com account with one click.
Under the hood, Crowdin.ai uses the same LLM that you could use directly. The difference is that the AI agent has a growing set of tools designed specifically for software localization tasks.
Crowdin.ai can be used for all common content types involved in software development. All resource files produced by your tech stack (e.g., Android, iOS, web resource files), .md or .html files make up your docs. For now, it does not work with any of Crowdin.com’s content connectors (such as HubSpot or Contentful).
It’s completely free during the beta period (and will remain free for all beta users forever), but we operate on a bring-your-own model, which may introduce a cost for the use of AI tokens from the LLM provider.
Crowdin.ai is built on top of Crowdin.com, which means you would need to sign up for Crowdin.com, and some of the actions would be performed in Crowdin.com, such as API token generation and account security management. When you sign up for crowdin.ai, a special license will be issued to your crowdin.com account. Registration is currently closed. Please, fill out the form to receive an invite.
Use Vector Databases to Improve AI Translation Quality
During our internal experiments with AI, we discovered a way to improve translation quality using vector databases. The idea is simple: AI can produce better translations if it has reference texts from the target language to guide it.
Meet the Vector Memory App. It allows AI to use related content from similar files as a reference. Instead of starting from scratch every time, AI looks at past examples to improve accuracy.
For example, if you’re translating a legal document, you can add a previously translated law as a reference. This helps AI better understand the style and context, leading to more precise translations.
We recommend using the app after consulting with our team. It’s not ready for very large projects yet, but it’s great for experiments. One of the best aspects of vector-based systems is that they don’t require translation memory. Reference files should be in the target language, but AI doesn’t require source documents.
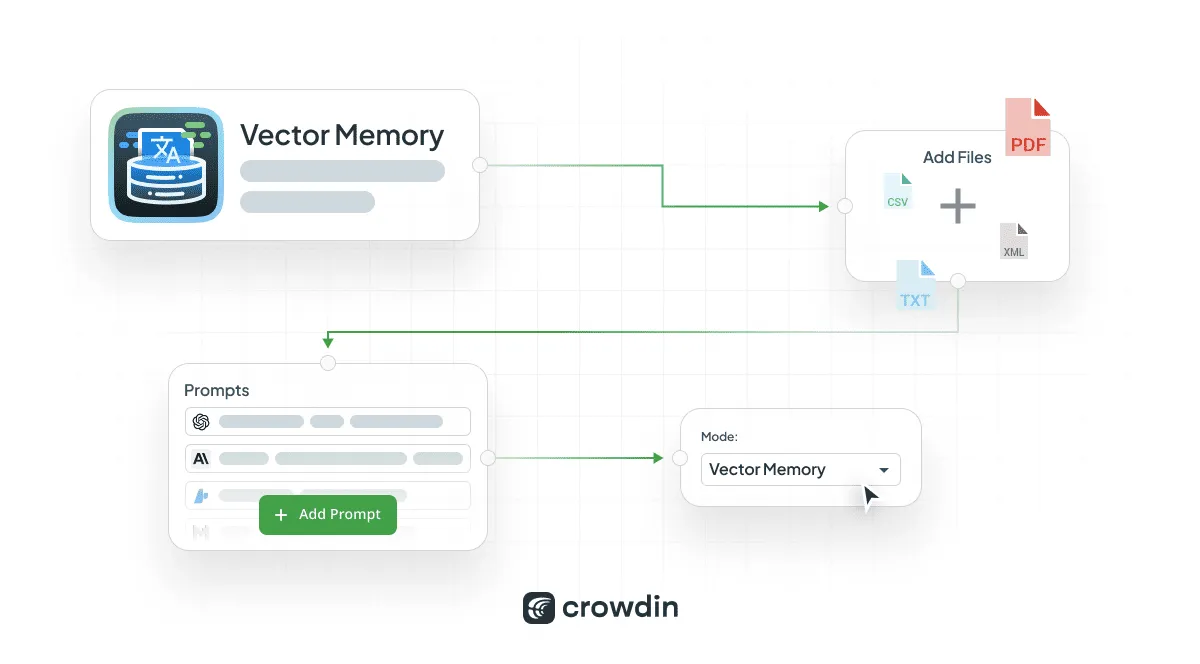
How to use Vector Memory app to improve AI translation quality
-
Install the Vector Memory App
Head to the Crowdin Store, find the Vector Memory App, and install it. -
Add Store
Go to app > Add Store. Upload files related to the topic of your current translation to the store. These should be good-quality translations of similar content, like a previously translated legal document if you’re working on another legal text. -
Set Up Your Prompt
Go to the AI section in Crowdin and create a new prompt. Important: Select Vector Memory as mode. If needed, you can add specific instructions the AI should follow in a prompt. -
Connect the Store
While creating the prompt, choose the store to the prompt. This will allow the AI to pull context from those documents during the translation process. -
Adjust Document Limits
Set the maximum number of documents the AI can reference. Based on our tests, we recommend starting with 4 documents for optimal results, but you can experiment to find the best setup for your needs. -
Run the AI Translation
With everything set up, start your translation and let the AI use your reference materials to provide more accurate and context-aware results.
Introducing Weighted Word Count in Reports
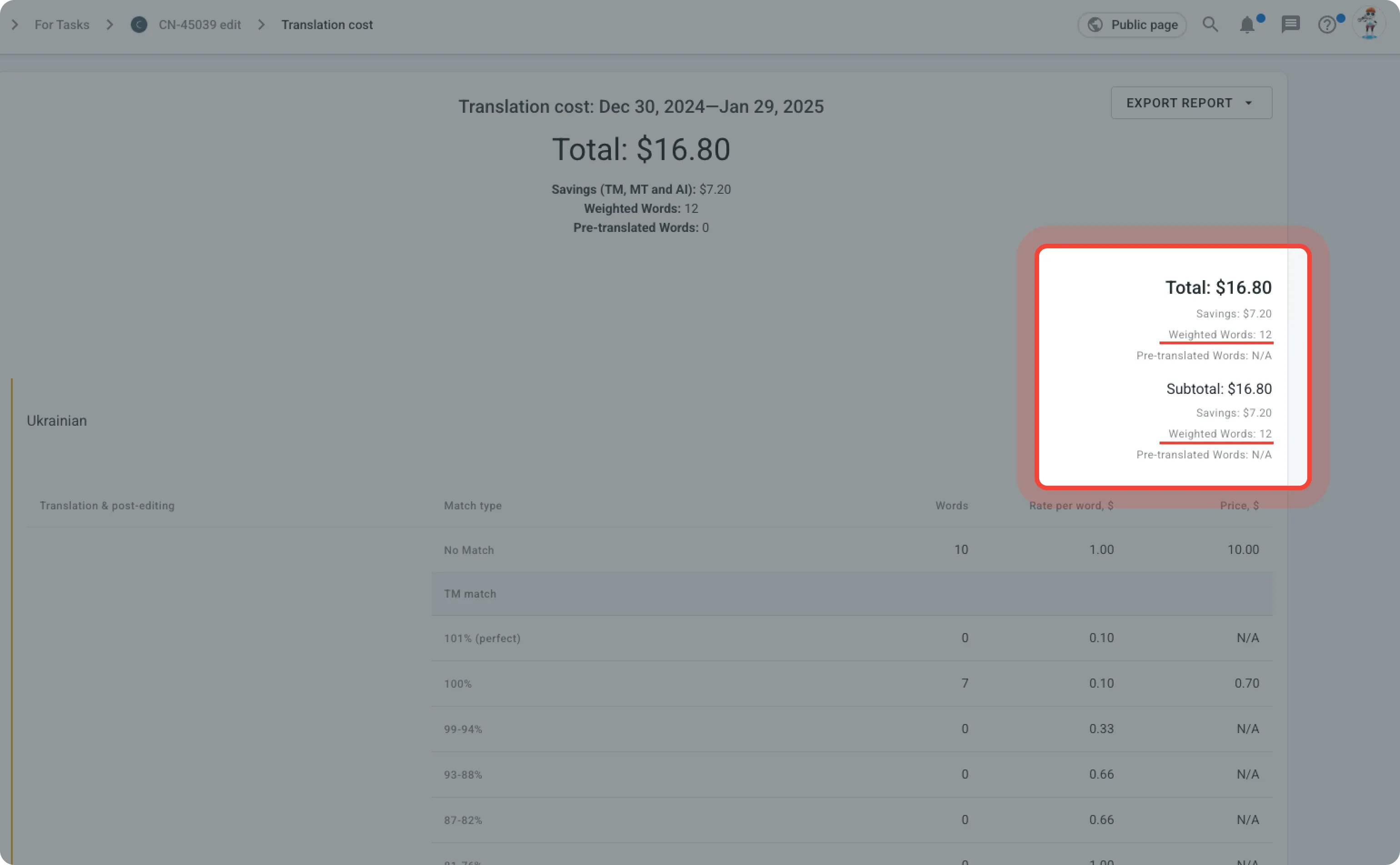
This month, we’ve added weighted word/character/string counts to the Translation Costs and Cost Estimate reports.
Sometimes, you need to estimate the workload without linking it to costs. A common way to do this is by using weighted word count, which adjusts word count based on the effort needed for translation. The following is a brief description of how it works
Each segment type is assigned a weight:
- 100% Matches & Repetitions — No editing, but requires reading to validate the translation (weight: 0.1-0.2)
- Fuzzy Matches (high confidence) — moderate effort (weight: 0.3-0.7)
- Fuzzy Matches (low confidence) — higher effort (weight: 0.8-1.0)
- No Matches — full effort (weight: 1.0)
For example:
500 words with 100% match × 0.1 = 50 weighted words
300 fuzzy matches (75—99%) × 0.5 = 150 weighted words
200 no matches × 1.0 = 200 weighted words
Total Weighted Word Count: 400
From now on, in Crowdin you can count weighted words, strings, or characters. The report will be calculated based on the unit selected in the report settings.
Crowdin Store: XAI Grok & DeepSeek for Localization
This month, we’ve added two tools you may already know, now available for integration into your translation process in Crowdin: XAI Grok and DeepSeek.
xAI Grok app: Integrate xAI’s powerful AI models and use it to pre-translate content, or apply it in the Crowdin translation editor and perform tasks like terminology extraction and translation quality control.
DeepSeek guide: While Crowdin doesn’t offer a dedicated DeepSeek integration, you can still use DeepSeek’s AI models via Crowdin’s OpenAI connector. Short step-by-step instructions are available at the Crowdin Store.
Editor: Small UI Tweaks, Faster Screenshots load, and Improved Filtering
We’ve made several improvements to the Crowdin Editor:
-
Faster Screenshot Loading — Large screenshots can slow down the editor, so we now optimize them automatically for smoother performance. If you need to download a screenshot, it will be available in its original size, not the optimized version.
-
Cleaner File Names — Uppercase letters have been removed, so file names in the editor now match those in the file tree.
-
Improved Advanced Filter — The advanced filter now includes indicators showing how many filter options are enabled, and active options are highlighted in bold for better visibility.
Adaptation of QA Checks for Different Language Pairs
We’ve improved QA checks to work more accurately across different language pairs. Previously, QA checks expected certain symbols to match the source text, often following English punctuation rules, which didn’t always fit other languages. Now, we’ve adjusted this to better accommodate language-specific punctuation and formatting rules for languages like Japanese, German, Arabic, and others, ensuring a more natural and accurate QA process. This update makes working with these languages easier and more efficient!
More Control Over Crowdin In-Context Initialization
We’ve updated the Crowdin In-Context tool to give you more control over when and how it starts in your project. You can now choose how In-Context is initialized using the start_type parameter:
default — Works as before, starting automatically when the script loads.
manual — A new mode that starts In-Context only when you call window.jipt.start().
This new manual mode gives you more control, making it especially useful for single-page applications (SPA) where you need to dynamically turn In-Context on or off based on user actions, delaying the start of In-Context until a specific event or user action happens, or preventing the automatic startup of In-Context if it should only run under certain conditions.
Additionally, you can use various methods to start, stop, and customize In-Context in real time to better fit the needs of your project.
For more details on the available methods, check out our In-Context Localization Documentation. This improvement is also important for customers who use In-Context not for actual translation, but for automatic screenshot capture during e2e testing.
Localize your product with Crowdin
Visibility for Failed Synchronizations in Integrations
We’ve improved how Crowdin Integrations handles failed file synchronizations. Now, if a file fails to sync, it will be clearly labeled to indicate that something went wrong. For example, in some cases, files get deleted on the integration side, preventing updates in Crowdin.
To keep you informed, we’ve added labels that show when a file was deleted. Soon, we’ll also introduce a filter to help you quickly find all files that failed to sync, making it easier to track and troubleshoot this kind of synchronization issue.
Other Small Updates
- Full native support for the new ChatGPT o3-mini model.
- We’ve added language information in the “Proceeding Tasks” dropdown to make it easier to search for tasks.
- We’ve added the ability to search API logs not only by application name but also by token name.
- We’ve added Prompt IDs and AI providers to the UI in Crowdin Enterprise, making it easier to manage AI-powered workflows.
- We’ve added an option to enable or disable the Top Members report in Crowdin Enterprise upon request.
- Now, you can sync articles between Kontent.ai and Crowdin based on their status. Choose workflow steps in the app settings to sync only what’s ready for translation, skipping drafts and reviews.
- We have added the addToTm parameter to the Add Translation API method. This parameter allows you to specify whether the newly added translation should be included in the translation memory (TM).
- Comments can now be added to plural forms in YAML files.
Localize your product with Crowdin
Crowdin Agile Podcast: New Episodes This Month
This month, we launched two new episodes of the Crowdin Agile Podcast.
- “Why Localization Tools Are Failing Buyers and How to Fix It” — Boryana Nenova discusses the challenges with current localization tools and how Crowdin solves them.
- “10 Languages, Zero Stress: Inside Edwin Trebels’ Localization Workflow” — Edwin Trebels from the Philadelphia Church of God shares how his team handles multilingual content, automation, and transparency.
Listen on Spotify, Apple Podcasts, and YouTube. And don’t forget to subscribe!

External Tools
In January 2025, we released new versions of:
- Go API Client v0.12.1, v0.13.0, v0.14.0
- CLI 4.5.1, 4.5.2
- GitHub Action v2.5.1, v2.5.2
- .NET API Client 2.27.1, 2.28.0, 2.29.0
- JS API Client 1.41.1
- Java API Client 1.20.0, 1.21.0, 1.22.0, 1.23.0
- Python API Client 1.20.0, 1.21.0
- Context Harvester 0.5.2
- Android Studio Plugin 2.2.0
- PHP API Client 1.16.0
- OTA Client JS 2.0.1
Localize your product with Crowdin
Diana Voroniak
Diana Voroniak has been in the localization industry for over 4 years and currently leads a marketing team at Crowdin. She brings a unique perspective to the localization with her background as a translator. Her professional focus is on driving strategic growth through content, SEO, partnerships, and international events. She celebrates milestones, redesigns platforms, and spoils her dog and cat.