Every night, while you sleep, your brain does something remarkable. It replays the day to extract signal from noise and form long-term memory. Raw sensory data gets compressed into patterns. Patterns become rules. Rules become the intuition you wake up with.
Neuroscientists call this memory consolidation. We call it dreams.
Crowdin has been observing recent developments in AI coding tools and we figured out that the very same principle might work for Crowdin.
Every time a human editor corrects an AI translation, something valuable is created: information about what kind of translations are acceptable for a particular project.
Source text. Machine output. Human decision.
Our industry almost always throws this away. We ran experiments, and it seems this is a great way to automate the improvement of expected translation quality.
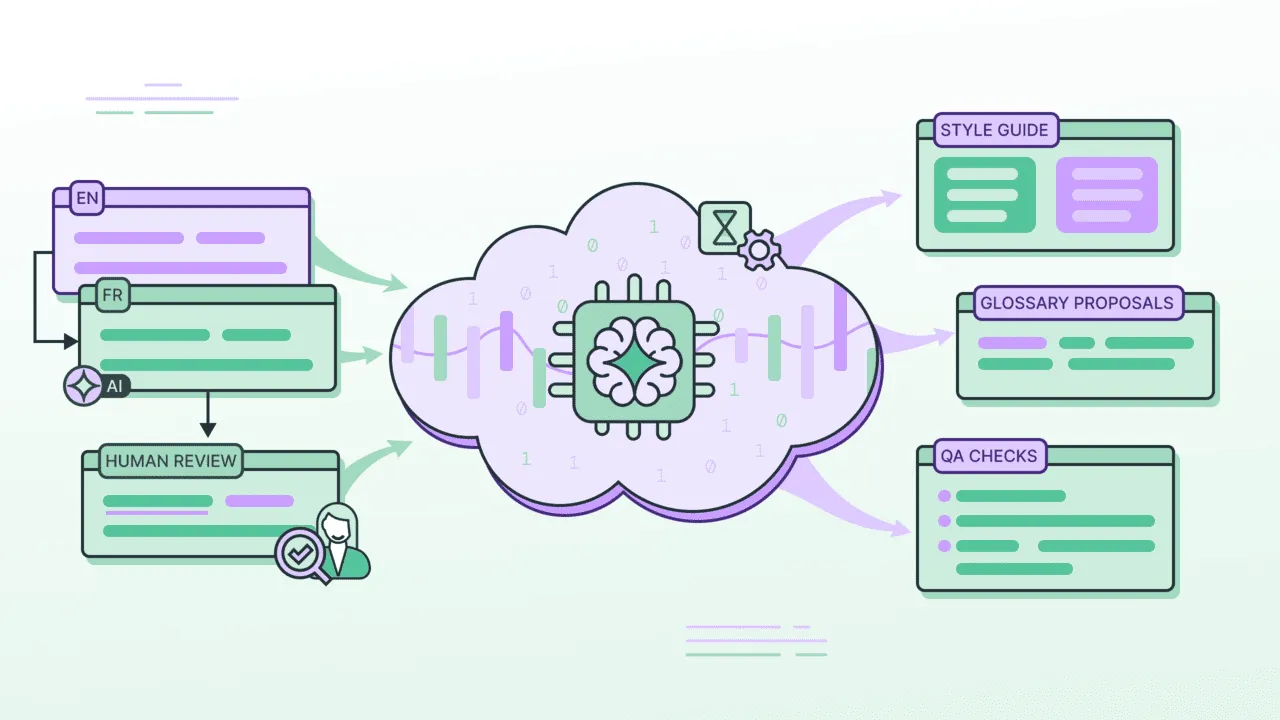
This is how it works
Crowdin Dreams is a background process that watches human edits as they happen, then, like a brain during sleep, tries to surface the patterns your team already knows but has never written down.
It proposes:
- Bilingual glossary term candidates that were noticed being applied consistently.
- Style guide additions inferred from editorial choices.
- Changes to the AI implementation method (might suggest one more step in the AI Pipeline, or an improvement to the prompt of an existing step).
- QA rules based on punctuation, formatting, and register patterns.
Experiments in game localization project
While researching, we experimented with one client on a game localization project.
Game localization is uniquely hard: short strings, no screenshots, minimal key-level context.
The sample was quite small - 150 strings, AI translations, and human edits. 7% of the project.
Even that small amount of data was enough to provide a lot of useful input for the AI setup.
A structural insight about placeholders
The game was full of strings like "Meet Frank at the [location]" that were causing problems in languages with locative case, because [location] was only available in nominative.
A linguist solved it by moving the placeholder: "[location]: Meet with Frank".
Dreams saw the pattern and proposed a style guide rule for all location-bearing strings.
A punctuation rule no one had written
Editors were consistently removing trailing periods from strings in the target language, even when the source had them. Dreams flagged this as a target-language convention and proposed a style guide addition.
Dozens of glossary candidates extracted from editorial choices, ranked by confidence.
After just 150 strings, the system understood what “acceptable” looks like in this project.
Join the experimental phase
We’re not publishing numbers yet - nor the feature itself.
But what we’re seeing suggests that a small amount of human review can teach the AI enough to significantly reduce the need for more of it.
Dreams is currently in an internal demo, and we have many open questions. The current process assumes pre-translation is done for an entire language before review. But if knowledge about what counts as an acceptable translation accumulates as review progresses, what should we do with existing pre-translations that haven’t been reviewed yet, knowing they likely contain mistakes?
We’re looking for early adopters to work through these problems with us. Solving them on real projects is probably the most productive path forward. If you’re already using AI Pipeline and your policies allow post-edited translations to be used for this kind of research, please reach out.
We’re not announcing a release date yet. This is a fairly new, experimental technology, and it looks like it has real potential. We’re sharing now mostly to collect feedback and find teams willing to try it early.